Attention 注意力机制
Attention 注意力机制
注意力机制是一个宽泛的概念(抽象表达),Q、K、V相互计算的过程就是注意力,但没有规定Q、K、V怎么来的。
例如,Self-Attention的Q、K、V来源于同一个输入矩阵X。
Cross-Attention的Q,K,V来源不同的矩阵。
引言
注意力机制(attention是人工神经网络中一种模仿认知注意力的技术。这种机制可以增强神经网络输入数据中某些部分的权重,同时减弱其他部分的权重,以此将网络的关注点聚焦于数据中最重要的一小部分。
就像玩王者荣耀时,当我们身为辅助时,所以其实我们应该将注意力更多放在射手身上,即提高射手的权重,你会根据射手的位置、状态(比如血量、是否被敌方英雄攻击等)来分配你的注意力,比如现在射手在线上,我们就得高度关注他;而假如他已经回城了,那我们就可以不那么关注他了。
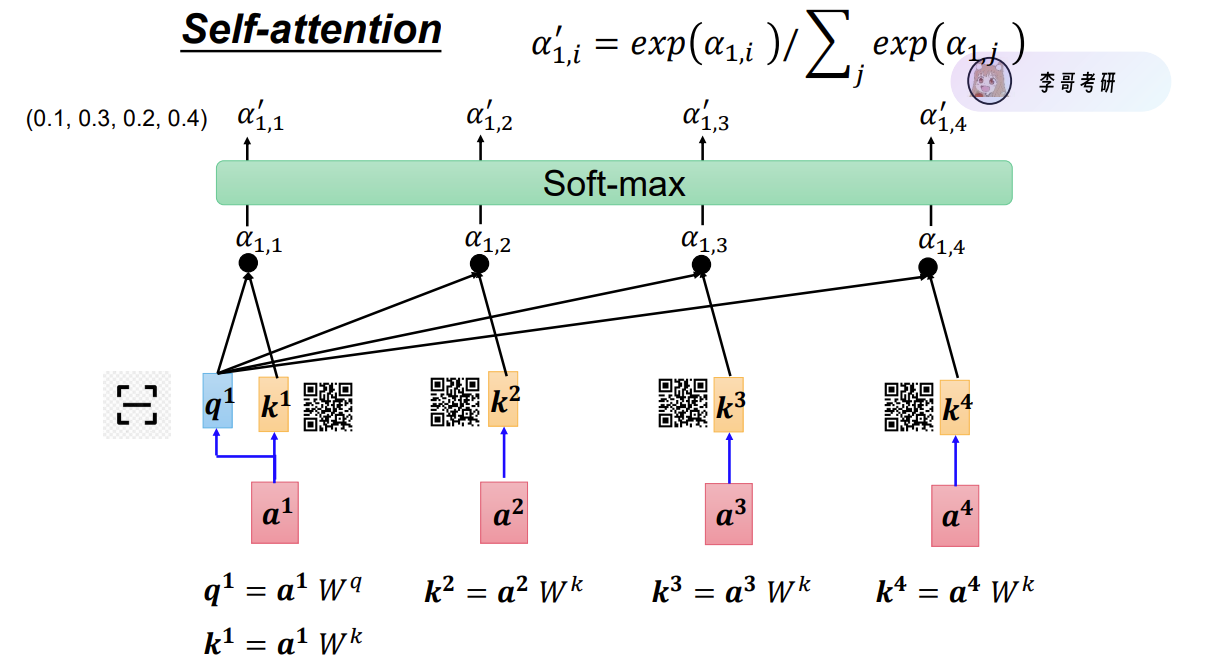
我们先以上面这个例子举例。注意力机制中有三个重要的矩阵:
Q矩阵
Q(query)矩阵就是用来发出自身需求的信号,比如作为辅助,我想知道“现在谁最需要我?”"我应该跟射手还是打野"。
K矩阵
K(key)矩阵是用来描述输入的特征,比如每个队友的血量、位置、是否被攻击等。
注意力得分与权重
我们通过计算Q与K的关联性,求得对应注意力得分Score,得分越高,意味着越需要关注,Q与K越相关。然后将Score进行归一化处理,得到注意力权重Weight。
Query(我要找谁) × Key(每个人的特征:位置、状态等)= Score(注意力得分)
例如你当前需求是“保护脆皮”(你的 Q)
那么:
- 射手正在被对抗路露娜摸到 → Score 非常高 70分
- 打野在刷红 → Score 中等 15分
- 中路健康、没人 → Score 很低 10分
- 上单在吃兵 → Score 几乎为零 5 分
最终通过归一化后得到注意力权重Weight:
射手:0.7 打野:0.15 中路:0.1 上单:0.05
实际上,上述的计算注意力得分与权重的算法都相对简单。实际过程中,我们通过使用
| 加性模型 | |
|---|---|
| 点积模型 | |
我们常使用缩放点积模型:
缩放点积模型相对于点积模型来说,为了缓解梯度消失的问题,会除以一个特征的维度。
在归一化时,我们常使用Softmax来进行,将得分变成权重的形式,权重加和为1。
缩放点积注意力
缩放点积注意力是Transformer的核心计算单元,公式为:
其中:
+
+
+
+
缩放因子
从输出可见,缩放后分数范围显著缩小,使
缩放点积模型代码实现
import torch
import math
def scaled_dot_product_attention(Q, K, V, mask=None):
"""实现缩放点积注意力"""
d_k = Q.size(-1)
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)
# 应用掩码(如Decoder中的未来信息屏蔽)
if mask is not None:
scores = scores.masked_fill(mask == 0, float('-inf'))
# 应用softmax获取注意力权重
attn = torch.softmax(scores, dim=-1)
# 加权求和得到输出
output = torch.matmul(attn, V)
return output, attn
# 数值示例:展示缩放的重要性
d_k = 64
Q = torch.randn(1, 1, d_k) # 单查询
K = torch.randn(1, 10, d_k) # 10个键
# 无缩放的点积
unscaled_scores = torch.matmul(Q, K.transpose(-2, -1))
print(f"无缩放分数范围: [{unscaled_scores.min().item():.2f}, {unscaled_scores.max().item():.2f}]")
# 输出类似: [-15.32, 12.67]
# 有缩放的点积
scaled_scores = unscaled_scores / math.sqrt(d_k)
print(f"有缩放分数范围: [{scaled_scores.min().item():.2f}, {scaled_scores.max().item():.2f}]")
# 输出类似: [-1.91, 1.58]V矩阵
得到注意力权重后,我们根据权重来关注我们需要的信息
例如他们能告诉你:
- 射手的具体位置、是否危险、是否需要保护
- 打野是否在准备开龙
- 中路是否要被抓
这些实际内容就是V(value)
Output
最后,我们会将
output就像辅助根据所有人提供的
你作为辅助会综合:
- 80% 的注意力来自射手 → 得到大量“射手位置、危险、血量”的信息
- 15% 来自打野 → 得到“是否要开龙”的提示
- 5% 来自中路 → 得到“中路现在安全不用支援”的信息
最终你得出新决策(output):
“先守住射手,再看能不能接打野的龙团”
总结:
| 概念 | 解释 | 王者荣耀类比 |
|---|---|---|
| Q | Q矩阵 | 你当前的需求(要关注谁?) |
| K | K矩阵 | 每个队友吸引注意力的特征 |
| Score | 注意力分数 | 你认为“该关注他”的程度 |
| Weight | 注意力权重 | 你分配给每个队友的注意力比例(权重) |
| V | V矩阵 | 队友实际给你的有用信息,决定了“之后应该怎么做” |
| output | 输出 | 你综合所有信息后的下一步决策 |
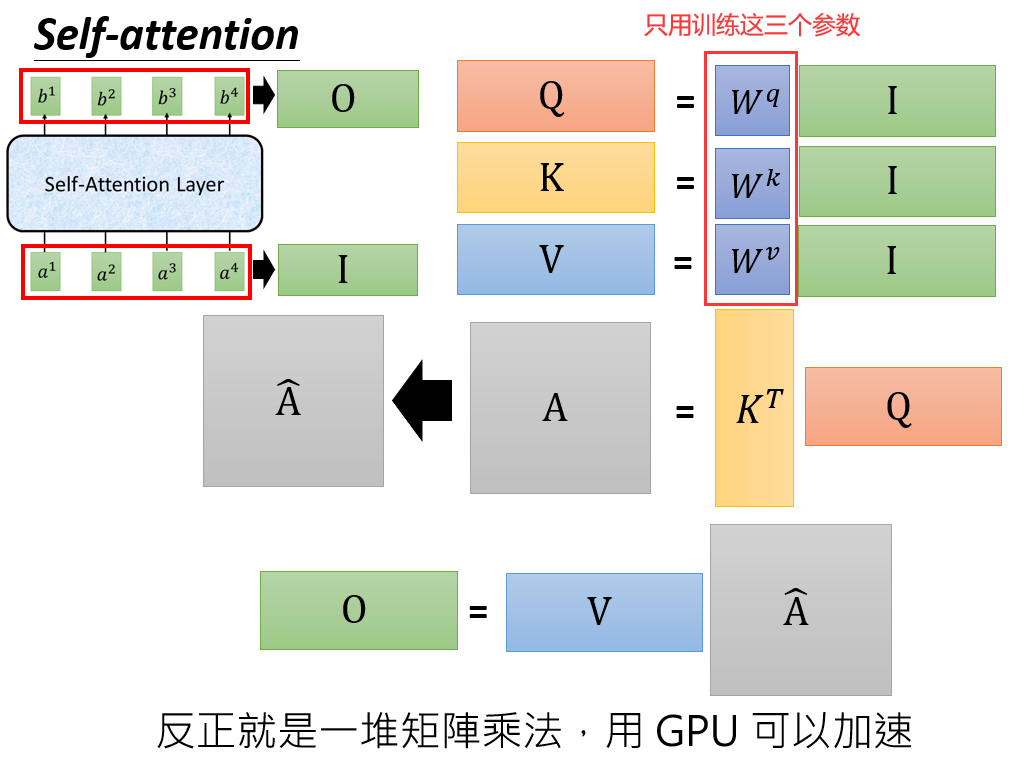
# 计算流程
score = Q × K^T / √d
weight = softmax(score)
output = weight × VSelf-Attention 自注意力机制
自注意力机制属于注意力机制的一种,其QKV本质上都来源于输入矩阵X,只不过是经过不同矩阵得到的。
概念
Self-Attention是Attention的变体,其特点是在Self-Attention中,Q、K、V均来源于同一输入序列。其本质是计算序列中每个位置与所有位置(包括自身)的关联权重,再加权融合所有位置的 value,得到每个位置的全局语义表示。
也就是说,让一句话自己内部的词之间互相关注。Self-Attention规定了QKV同源,也规定了QKV的之间计算的方法。
通过不同的
只有
这种并行计算的方式,不依赖前一个完成。
Self-Attention对比RNN & LSTM
RNN使用记忆单元Cell,存储和传递消息。
LSTM使用门控单元(输入、遗忘、输出),用于控制信息的流动和更新。
虽然RNN和LSTM能够在一定程度上解决问题,但仍存在速度慢的问题,就像你读书时只能一个字一个字读,Self-Attention使我们能一下子看到完整文章,输出结果。
- 并行计算能力强
- RNN / LSTM都必须按时间顺序,串行处理,如果上一个词没有处理完,没法对下一个词进行计算。
- Self-Attention 所有词之间的关系通过一次矩阵就能算完,支持GPU并行处理,速度快。
- 更好捕获“长距离依赖”
- RNN / LSTM 仍是逐步传递信息,而信息的传递过程中经过多个时间步传递,而步数越多,梯度越容易爆炸或消失。也就是越到后面越容易忘记前面。
- Self-Attention 每个词都可以直接关系句子中的任何其他词,无论距离多远,都相当于是一步跳过去
- 不会因为句子位置不同导致性能变化
- RNN/LSTM 会天生偏向最近的词。
- Self-Attention 是对整个序列全局加权,不偏向位置。
Masked Self-Attention
在Self-Attention上做了改进,为什么要做这个改进?生成模型,生成单词,一个一个生成,
当我们做生成任务时,attention在训练时能看到全部的句子,但是在预测/生成时,不能让模型看到整个句子,所以要把后面的盖(掩盖)起来
什么是Masked Self-Attention
Masked Self-Attention 是 Self-Attention 的一种特殊版本,它在注意力矩阵里 人为地遮挡(mask)掉序列中未来的词,让模型 不能看到后面的信息。
简而言之:Masked Self-Attention = 只能看自己和过去,不允许看未来。
为什么需要Masked Self-Attention
在文本生成中,模型需要一边生成,一边预测下一词,这是我们想要达到的结果。
那么如何在训练时,让模型学会这种方式呢?如果直接让模型看到整个句子的话,是无法完成训练的,因为这就相当于暴露了之后的词。因此我们通过在训练时使用causal mask(下三角 mask) 强制实现。
例如,训练语句为:我爱吃柚子。
当输入”我“时,应该让模型学会输出”爱“,因此就不能让模型看到“我”后面的词:“吃柚子”。
必须禁止它在预测时看到未来:
- 在预测 “爱” 时 不能看到后面的 “吃柚子”
- 在预测 “吃” 时 不能看到 “柚子”
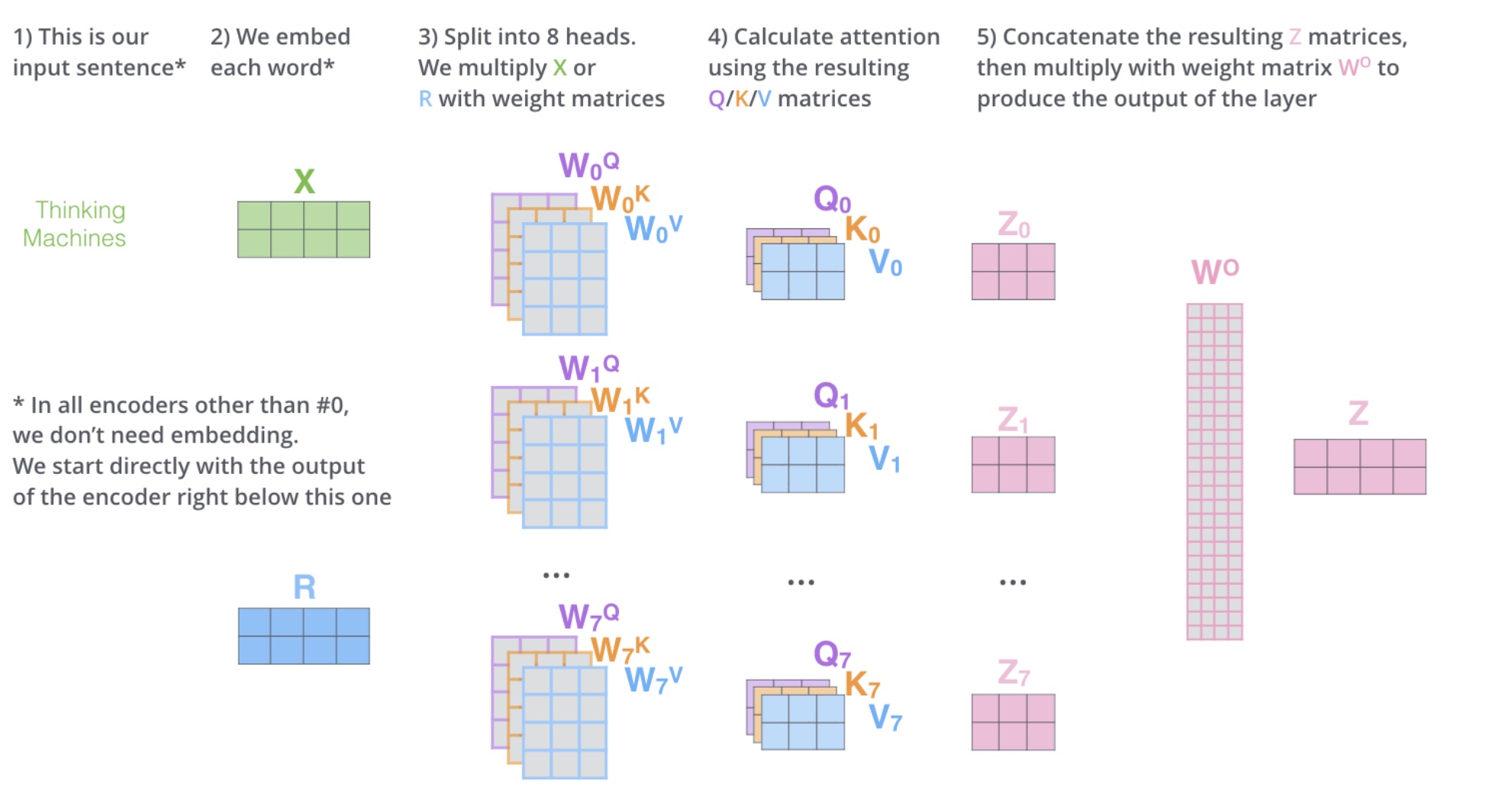
Multi-Head Self-Attention
多头注意力 = 多个“不同视角”的注意力机制并行工作,然后把结果拼起来。
为什么要多个视角?
- 一个注意力头只能关注输入中一种关系(例如“主语-谓语”)
- 多个头可以同时关注不同关系(例如“主语-宾语”、“语义相似性”、“位置关系”、“情绪”等)
如何实现多头
多头注意力将注意力机制并行运行多次,然后合并结果:
- 线性投影生成 Q、K、V并线性投影到 head 个子空间
- 在每个子空间独立计算注意力, 每个头做 Scaled Dot-Product Attention
- 将结果拼接并通过线性变换整合
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads):
super().__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
# 线性投影层
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
def split_heads(self, x, batch_size):
"""将特征维度拆分为(num_heads, d_k)"""
x = x.view(batch_size, -1, self.num_heads, self.d_k)
return x.permute(0, 2, 1, 3)
def combine_heads(self, x, batch_size):
"""将多头结果合并"""
x = x.permute(0, 2, 1, 3).contiguous()
return x.view(batch_size, -1, self.d_model)
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# 线性投影
Q = self.W_q(Q)
K = self.W_k(K)
V = self.W_v(V)
# 拆分为多头
Q = self.split_heads(Q, batch_size)
K = self.split_heads(K, batch_size)
V = self.split_heads(V, batch_size)
# 缩放点积注意力
attn_output, attn_weights = scaled_dot_product_attention(Q, K, V, mask)
# 合并多头
attn_output = self.combine_heads(attn_output, batch_size)
# 最终线性变换
output = self.W_o(attn_output)
return output, attn_weights
# 示例使用
mha = MultiHeadAttention(d_model=512, num_heads=8)
Q = K = V = torch.randn(2, 10, 512) # [batch_size, seq_len, d_model]
output, attn = mha(Q, K, V)
print(f"多头注意力输出形状: {output.shape}") # torch.Size([2, 10, 512])
print(f"注意力权重形状: {attn.shape}") # torch.Size([2, 8, 10, 10])多头注意力允许模型在不同表示子空间中关注不同位置,捕捉更丰富的信息。
多头注意力机制总体流程